
This post was originally written by Adriel Trott, Associate Professor in Philosophy at Wabash College and participant in the HuMetricsHSS "The Value of Values" (#hssvalues) workshop. It reflects her experiences of the event. We've cross-posted this from Adriel's blog, with her permission.
I just got back from a three-day workshop in East Lansing whose goal was to bring together people from diverse locations within the academy and adjacent to the academy to think through a proposed set of values for measuring humanities research in the academy.
The HuMetricsHSS team had developed this framework at TriangleSCI. Now they wanted to see whether people agreed that these were the shared values that people in the humanities have. They invited chairs and faculty from public research institutions, land-grant institutions, small liberal arts colleges, community colleges, and librarians and people working at Academic Research Centers on college campuses, and graduate students. For the tl;dr, skip below.

I was a little skeptical going into the workshop. I was skeptical that we could reach agreement. I was skeptical about whether we should want metrics at all. I was skeptical that these conversations could produce real change in academic culture.
Pre-Reading: Against Excellence
The pre-reading materials helped reduce the skepticism. When I read Cameron Neylon et al.'s critique of "excellence" as a metric for academic work, I realized that the HuMetricsHSS was challenging some fundamental orthodoxies of academic life. The authors of "Excellence R Us: University Research and the Fetishization of Excellence," published in Nature, argue that issues of reproducibility, fraud and homophily can be traced to the pervasive demand for excellence in the academy. They argue that the use of "excellence" encourages a concentration rather than a distribution of resources, which results in a tendency to produce similar work to what is established and a failure to recognize good quality work and the possibilities that arise from it. The authors argue that while excellence is anti-foundational in the sense that each evaluator has a different sense of what she seeks when looking for excellence, nonetheless the term can be evaluated in terms of how it is used in evaluation processes. But they reject this possibility when they find that because it lacks content it serves only as a comparative claim of success. This analysis explains why the term is a problem, but the authors proceed by arguing that reviewers do not have a good track record for recognizing excellence when that is measured in terms of the impact of scientific studies and that excellence as a standard produces negative effects on the ground. Negative effects include: bibliometrics — the standard used to measure impact on the field — motivates people to elevate citations to serve the metrics rather than to produce quality leading to "citation cartels," where people agree to cite one another in order to pump up their metrics, and referencing work critically still elevates the metrics because it is yet another reference; it disincentivizes the very things that we say are necessary for research to be good, like in the sciences, replication studies, and people are rarely rewarded for publishing their failures, though that is still a form of knowledge production; and it favors work that is very close to previous work. They propose a shift to standards of quality, credibility, and soundness. Because the standard of excellence tends to carry with it the notion that work is like the previous work, evaluating work in terms of quality, credibility and soundness allows peer reviewers to consider whether the work is thorough, complete and appropriate rather than flashily superior. Soundness shifts the evaluation to the process rather than to the output or the actor.
The Value of Process
The shift to evaluating process became a common theme in our discussion of valuing values. Another source of my skepticism was that I could not see what kind of process could lead to insight about what we value when a group of people who did not know one another were brought together to talk about what we valued. We were given several principles for how to conduct ourselves. Engage in "blue sky thinking" — think of the world how we want it to be, rather than as it is, in order to think about what we would want before being derailed by the realities of the world we face. Practice good faith — assume that others speak genuinely out of a desire for a better world. These principles seem simple, but it was both hard and productive to keep them at the forefront. It allowed people to speak up about their disagreement without that disagreement being viewed as an effort to derail a process.
The organizers of the workshop divided us up and gave us a stack of cards with values written on them, some from the core values and the subcore values on the chart above and some from what we had developed at the workshop in brainstorming how we would want to see people engage in certain projects like serving on a committee. Then we had to organize the values in terms of what we most cared about. This work was hard. Not because we couldn’t do it, but because we had to find ways to agree and to listen to what we each had serious concerns over. In my group, some people argued against including personal characteristics as values because people recognized how a demand for kindness or compassion can silence oppressed voices when they criticize the system. We returned to that theme over and over and found that one thing we did agree on as a group is that values we consider positive are often used by institutions to perpetuate the status quo. The sense was that any value that becomes sedimented and is not up for re-evaluation can become a bludgeon by which to control others.
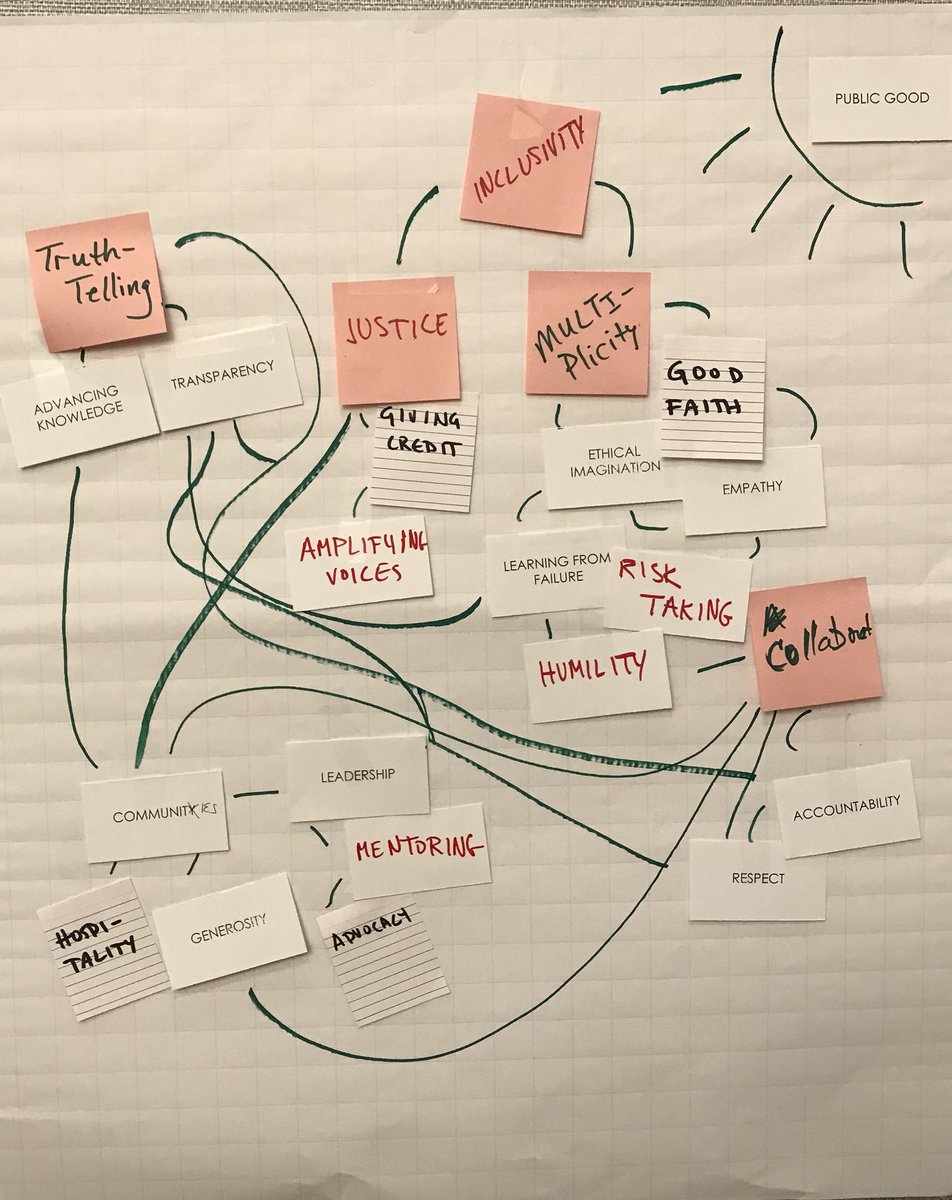
One part of the process that I found fruitful was the conclusion: the organizers brought in sympathetic colleagues who had not participated in the workshop to hear groups report on the specific principles they wanted to put into place around a particular process in light of the ways that we had organized our values. My group, for example, went from our values to what principles we think should be followed in writing a scholarly article. The pink post-its (in the photo above) were the core values that the other values further specified with public good being the overarching organizing value. From that discussion, we were able to develop our principles for writing a scholarly article.
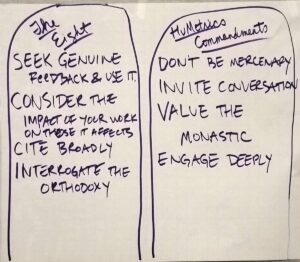
After reporting on our work, the outside listeners noted several interesting things. One noted that a case could be made, and research should be done to show whether having a process that was committed to these values leads to better scholarly work. For example, citing broadly makes your work better because you have to consider multiple possible perspectives of disagreement to your work. Another important point that was reflected back to us was that there could be indicators of good work that might not be proof — that is, someone could contest that those indicators meant one thing rather than another, but they might still be suggestive. For example, evidence that certain steps were taken in the process could be indicators that the final product was better work than where those indicators could not be shown, as for example, whether feedback was sought and incorporated.
Metrics: Scaling and Transferring
The evening after the workshop, I had dinner with some friends, an academic and a non-academic. I was sharing my enthusiasm about the possibilities from the workshop and we began to talk about how and whether this process could be put to work to think about metrics in teaching. In general, my colleagues at a small liberal arts college are rightfully skeptical of many models of assessment that are used to make a case to accrediting agencies but aren’t believed to capture whether we are teaching well. Part of the problem that came up just last night is that faculty are often not asked what they want to achieve in the classroom and then asked to consider how they might measure whether they are achieving it. We started talking about possible things we might want. I suggested that I want students to be excited about thinking. And then we started talking about possible ways of measuring that: students take a second class with me, students encourage their classmates to take my class, students come talk to me about what they are thinking about. All of these things would be indicators. But of course, they could mean other things too. Students could take another class because a professor is an easy grader (is there even evidence that students do take more classes with easy graders? I’m not even sure it is true). These other possibilities made me think that the metrics might not be the problem altogether, but our notion that they tell us the whole story might be the problem. If faculty could communicate indicators and then offer a narrative for possible meaning, we could see we have some more information, but it remains the faculty judgment regarding what is happening. And that's ok.
Another problem that Neylon et al. discuss, that we talked about at the workshop, and that my colleagues quickly came to in our conversation last night, is that it is so easy for metrics to determine the practices. You get what you measure, as they say. So if you measure students taking another class as evidence that they are enthusiastic about the work, then you push to get them to take your courses. Maybe you cater to them a little bit and maybe you become an easier grader. This situation could be a reason to resist metrics, since even metrics that seem unmanipulable, like citation practices, lead to things like citation cartels. Perhaps one alternative is to allow for multiple indicators.
tl;dr: Take-aways
- After the conference, I was tweeting about the possibilities of this project, when someone responded with a critique of metrics. Here's where we have to think post-blue sky thinking. I told someone that now we needed the anti-blue sky thinking workshop where we talk about all the avenues of resistance. But I'm not sure that not having metrics is better. It could be just as likely that relying on the good judgment of others will just as likely reproduce the orthodoxies and the current order of things. I have been wondering whether a process that encourages better metrics while also narrative analyses in reviewing of what those metrics might indicate and what they might not indicate in order to allow for more just, inclusive, truth-telling collaborative work to be done.
- Contestation, negotiation. It seemed that we all agreed that in a blue-sky world we want to continue to contest and negotiate our values. When we cease to think they need to be contested, we overlook who might be excluded. My own work on Aristotle has argued for working toward instituting processes that encourage contestation and negotiation over what is good and whether and how what we are doing is getting us to what we determine to be good. The question is whether that value can be measured and whether we can proceed toward good work when our values are continuously being contested and negotiated.
- Implementation. We had many questions about scale and transferability of this project. Can it scale to the multiple communities in which we work? How can we change the culture when powerful people and institutions benefit from the current system? What do the next steps look like? My sense is that Mellon is strongly supportive of this project and Mellon can influence accrediting agencies and presses to adopt processes that might be more reflective of humane values. I think it is worth it. The capacity of the academic world to become more humane depends on it.